

ことばの波止場
Vol. 4 (2018年9月発行)
コーパス開発センター

コーパス開発センターのしごと
コーパスの開発には、言語学的な知識・工学的な技術・経営学的な生産管理の三つが必要になります。それぞれ特殊な技能が必要ですが、コーパス開発センターはコーパスの整備に必要な技能を持つ人員により構成されています。
コーパス開発センターは従前より国立国語研究所で整備してきたコーパスおよびツールの公開・維持・管理を行います。コーパスである『日本語話し言葉コーパス』『現代日本語書き言葉均衡コーパス』『国語研日本語ウェブコーパス』、辞書である『UniDic』『分類語彙表』、検索ツール「少納言」「中納言」「梵天」などが対象です。
コーパス開発センターは先進的なコーパスの整備を進めています。係り受けの国際的な標準であるUniversal Dependenciesのツリーバンク、分類語彙表を用いた意味情報付与コーパス、視線走査装置を用いた読み時間コーパス、音声データベースなどの開発を進めています。また、研究系の各領域においても新しいコーパスの開発を行っています。これらを一括で検索可能なツールの開発もしています。それに向けて、研究所内のコーパス開発プロジェクトに対して、様々な形で支援を行うのもコーパス開発センターのしごとの一つです。
既存コーパスの維持管理
『日本語話し言葉コーパス(Corpus of Spontaneous Japanese : CSJ)』(図1)は、日本語の自発音声を集めて研究用情報を付加した話し言葉研究用のデータベースです。国立国語研究所・情報通信研究機構・東京工業大学が1999年~2004年に共同開発したもので、音声情報処理、自然言語処理、日本語学、言語学、音声学などの分野で利用されています。

音声データ661時間、転記テキスト752万形態素と世界有数の規模です。節単位情報、分節音・イントネーションラベル、係り受け構造などが含まれたUSBを有償頒布しています。
『現代日本語書き言葉均衡コーパス(Balanced Corpus of Contemporary Written Japanese : BCCWJ)』は、現代日本語の書き言葉の全体像を把握するために構築したコーパスであり、現在、日本語について入手可能な唯一の均衡コーパスです。2006年~2010年に国立国語研究所で開発しました。書籍全般、雑誌全般、新聞、白書、ブログ、ネット掲示板、教科書、法律などのジャンルにまたがって1億430万形態素のデータを格納しており、各ジャンルについて無作為にサンプルを抽出しています。国語研が規定した短単位・長単位の2種類の単位に形態論情報が付与されています。DVD-R 4枚組のデータを有償頒布しています。
『国語研日本語ウェブコーパス(NINJAL Web Japanese Corpus : NWJC)』は、ウェブを母集団として構築した大規模テキストコーパスです。2011年~2015年に国立国語研究所で開発しました。3か月ごとに1億URLをウェブクロールすることで、250億語規模の形態素解析・係り受け解析済みデータを後に述べる検索系を介して言語研究に利用できるようにしています。また、語彙表なども無償公開しています。
検索ツールの維持管理
コーパス開発センターは「少納言」「中納言」「梵天」と呼ばれる3種類の検索ツールを公開しています。
「少納言」はBCCWJを公開するために開発されたウェブ上で利用可能な文字列検索ツールです。登録しなくても利用条件に承諾できる方はどなたでもご利用になれます。
「中納言」は短単位・長単位・文字列による三つの検索が利用できるウェブアプリケーションです(図2)。CSJ・BCCWJの他、現在開発中の「日本語歴史コーパス(Corpusof Historical Japanese : CHJ)」「多言語母語の日本語学習者横断コーパス(International Corpus of Japaneseas a Second Language : I-JAS)」が検索できます。その他、国語研に移管された「名大会話コーパス(Nagoya University Conversation Corpus : NUC)」や「現日研・職場談話コーパス(Gen-Nichi-Ken Corpus ofWorkplace Conversation)」が検索できます。CSJは、有償版購入者のみ音声配信サービスが利用できます。またCHJは、国語研所蔵の原文の画像・小学館の「ジャパンナレッジ」ほか他機関の原文画像へのリンクを利用することができます。なお、中納言の利用には登録が必要です。

〜文字列・品詞列に基づく検索が可能
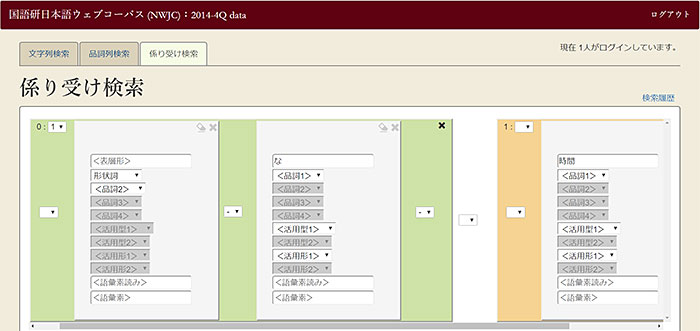
「梵天」はNWJCを公開するために開発された検索ツールです(図3)。一般公開版では250億語規模のテキストから高速に文字列検索できます。高機能版では形態論情報や係り受けに基づく高度な検索が可能です。背景色で係り受け関係を表したり、形態論情報がポップアップで表示されたりします。ダウンロードして、コーパス管理ツール「ChaKi.NET」で開くとより高度な分析が可能です。なお、高機能版の利用には講習会の参加が必要です。
語彙資源の維持管理
コーパス開発センターではコーパスだけでなく二種類の語彙資源を整備しています。一つは『UniDic』で、もう一つは『分類語彙表』です。
『UniDic』とは、国立国語研究所の規定した斉一な言語単位(短単位)と、階層的見出し構造に基づく電子化辞書設計方針および、その実装としてのリレーショナルデータベースであるUniDicデータベースと、そのデータベースからエクスポートされた短単位をエントリ(見出し語)とする、形態素解析器「MeCab」用の解析用辞書解析用UniDicの総称です。コーパス開発センターでは、国語研所内で開発されるコーパスに形態論情報を付与する際に、その形態論情報に関する情報を管理するとともに「Unidic Explorer」と呼ばれるデータベースを介してUniDicデータベースの情報を各プロジェクトに提供します。同データベースからエクスポートされた解析用UniDicは『現代書き言葉UniDic』『現代話し言葉UniDic』『古文用UniDicS』を公開しています。解析用GUIとしてWindows OSで動作する「ChaMame」と「Web茶まめ」の2種類を無償公開しています。

『分類語彙表』とは、「語を意味によって分類・整理したシソーラス(類義語集)」です。昭和39年(1964年)に出版された初版『分類語彙表』(現在は絶版)は、現代日本語の本格的なシソーラスとして幅広く活用されてきました。その後、収録語数を増やした『分類語彙表−増補改訂版−』が刊行されましたが、研究開発用にそのデータベース版を用意しています。
2018年2月にこの二つの語彙資源をつなぐ、新しい語彙資源『wlsp2unidic』を公開しました。分類語彙表番号とUniDicの語彙素番号の対応表で、これを利用することで形態素解析とともに、その語彙素に対して割り当て可能な分類語彙表番号を自動展開できるようになりました。「ChaMame」のオプションを用いることで、プログラムを書かなくても分類語彙表番号付与ができるようになりました。
プロジェクト : 「日本語言語資源の包括的高度共同利用環境の整備」
コーパス開発センターでは、管理業務のほかに研究も進めています。一つは国語研のコーパスの共同利用を進めるためのプロジェクト「日本語言語資源の包括的高度共同利用環境の整備」です。
検索ツール「中納言」をベースとして、さまざまな機能追加をすすめており、CSJの音声配信機能やBCCWJやI-JASの付加的情報のダウンロードサービスなども本プロジェクトの成果です。
また2021年度までに、「中納言」に登録されているコーパスを横断検索するシステムを構築します。
プロジェクト : 「コーパスアノテーションの拡張・統合・自動化に関する基礎研究」
もう一つは共同研究プロジェクト「コーパスアノテーションの拡張・統合・自動化に関する基礎研究」です。コーパスを用いた先進的な研究を進めるためには、付加情報が不可欠です。その中でも扱いに技術を要する統語・意味・音声の三つのアノテーションを研究対象として、他機関との共同研究を進めています。

統語班(係り受け班)は、国際的な係り受けアノテーション基準Universal Dependencies(UD)に基づく日本語の言語資源整備を進めています。UDは2014年にはじまったオープンコミュニティで、古語・危機言語を含む60言語以上のデータを公開しており、国際会議CoNLL-2018の多言語依存構造解析のShared Taskのデータセットとして利用されています。その他、係り受け構造付きデータを用いた基本語順の研究などを進めています。

意味班(語義班)は、『分類語彙表』を中心とした言語資源整備を進めています。現在、BCCWJ・CSJ・CHJに対する分類語彙表番号アノテーションを進めています。同アノテーションデータを用いて、単語に対して意味情報を悉皆付与するallword WSDの技術について研究を進めています。これにより、コーパスが「意味」により引けるようになります。また、同データを用いた、比喩表現の調査を進めています。
音声班は、音声コーパス整備に必要な技術の研究を進めています。音声の時間情報と書き起こしとの対応関係を取る、テキスト―音声アラインメントの環境を整備して、研究所内のコーパス開発の支援を行っています。また、音声分析用のフリーソフトウェアであるPraatのコーパス開発への適用などについて助言を行っています。研究としては、日本語・中国語・モンゴル語の音声データベースの整備や、調音運動データベースの構築を進めています。
言語資源活用ワークショップ
国語研で整備しているコーパス・語彙資源を用いた研究に関する情報交換をする場として、また、二つのプロジェクトの成果を発表する場として、毎年9月に「言語資源活用ワークショップ」を開催しています(初回の2016年度開催分のみ3月開催)。発表論文は、「国立国語研究所学術情報リポジトリ」に掲載されます。また2017年度開催分から、学生の発表に対して、互選に基づく優秀発表賞を設定しました。
さらにワークショップの前後に特定のテーマを取り扱うシンポジウムも開催しています。2016年度は、「語彙資源活用シンポジウム」と題し、紙の辞書・電子化辞書のそれぞれの専門家を招いて、辞書に関する様々な話題を提供してもらいました。2017年度は、国立情報学研究所データセット共同利用研究開発センターと共同で「音声資源活用シンポジウム」を開催しました。2018年度は、「コーパスとしてのウェブテキストシンポジウム」を開催しました。
さらにワークショップの前後には各種ツールの講習会も企画しています。
コーパス開発センターウェブサイト : http://pj.ninjal.ac.jp/corpus_center/
PROJECT 言語資源の整備と研究成果発信
コーパス開発センター
浅原正幸
ASAHARA Masayuki
あさはら まさゆき●准教授/専門は自然言語処理。奈良先端科学技術大学院大学修了、博士(工学)。2012年に本研究所着任。