

ことばの波止場
Vol. 13-2 (2024年4月公開)
特集 : BCCWJ(現代日本語書き言葉均衡コーパス)開発秘話

現代日本語の書き言葉の全体像を把握する──そのために国立国語研究所(国語研)が構築し、2011年より公開したのが、「現代日本語書き言葉均衡コーパス(Balanced Corpus of Contemporary Written Japanese : BCCWJ)」です。
約1億語からなる、日本語書き言葉の全体をバランスよく反映した2024年現在唯一のコーパス。その開発は試行と挑戦の連続でした。
コーパスとは?
コーパスとは、実際に使われた言葉を大量かつ体系的に集め、品詞情報など研究用の情報を付加してさまざまな検索ができるようにした、言葉のデータベースです。
野菜の「たまねぎ」は、どう書かれている? 「○○的」という言葉には、どのようなものがある? コーパスを使うと、そうした言葉の使われ方を調べることができます。


(BCCWJの元データによる「/○○/的」の検索結果)
世界各地でコーパスが次々に誕生
言葉を研究するには、言葉を集めて分析する必要があります。研究者はそれぞれの目的や関心に従って言葉を集めますが、個人では集めることができる量や範囲は限られます。そこで、多様な目的に利用できて言語研究の共通基盤となるように、言葉を大量かつ体系的に集めたコーパスを、大学や国が中心となってつくり始めました。
世界初の大規模なコーパスは、イギリスの「Survey of English Usage Corpus(SEU)」です。1959年から話し言葉と書き言葉それぞれ50万語の収集を始め、紙のカードに言葉を書き取って整理する方法でつくられました。
1964年にはアメリカで、100万語の書き言葉を収集した「Brown Corpus」が完成しました。コンピュータで使えるようにした、世界初の電子コーパスです。その後、世界各地でコーパスが開発され、1994年にはイギリスで話し言葉と書き言葉を合わせて1億語を集めた「British National Corpus(BNC)」が完成しました。
1億語の日本語書き言葉コーパスをつくろう!
国語研では1950年代から、雑誌や新聞などを対象に、言葉の使われ方や頻度を調べる語彙調査を行ってきました。それらは紙のカードを用いたものでした。2004年には国語研初の電子コーパスとして「日本語話し言葉コーパス」が完成しました。しかし、日本語の書き言葉の全体をバランスよく反映したコーパスが、まだありませんでした。
そこで、BNCの日本語版を目指し、「1億語の書き言葉コーパスをつくろう!」というプロジェクトが文部科学省科学研究費補助金(特定領域)の助成を受けて2006年に始まりました。
目指したのは現代日本語の書き言葉の縮図

新規にコーパスをつくる場合、どういう性質のコーパスとするのか、その設計方針が重要です。多くの議論を経て、次の4点を念頭に置いて設計することにしました。
- 多様な書き言葉をバランスよく反映したコーパス
- 幅広い目的に供するコーパス
- 公開可能なコーパス
- 先に公開した「日本語話し言葉コーパス」の解析単位との互換性を保持
1億語をどう選ぶ?
書き言葉にはさまざまなものがありますが、活字になって刊行されたものを対象とすることにしました。具体的には、書籍・雑誌・新聞です。では、どのようにサンプリングすれば、日本語の書き言葉を代表するサンプルを収集できるのか。それが大きな課題でした。
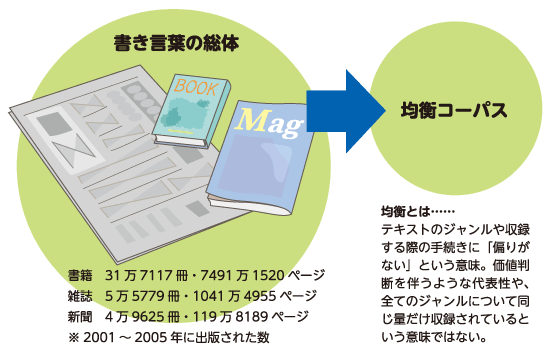
そして導き出した方法が、「2001~2005年に出版された全ての書籍・雑誌・新聞に含まれる総文字数を推計し、その比率をもとに各媒体からサンプリングする言語量を設定する」というものです。推計する対象として、書籍は国立国会図書館の蔵書目録にあるもの、雑誌は日本雑誌協会の加盟出版社発行のもの、新聞は全国紙・ブロック紙・有力地方紙としました。
文字数をひたすら数える!

*クリックで拡大します。
5年間に出版された書籍・雑誌・新聞に含まれる総文字数をどのように推計したと思いますか?
新聞については、全国紙4紙の朝夕刊の8冊・211ページを実測しました。右の写真は、実際に文字数を数えた新聞です。エリアを区切り、1文字1文字、ひたすら数えていきます。エリアごとの文字数が鉛筆で書き込まれています。このページの文字数は5,320字でした。
書籍については、日本十進分類法(NDC)の分類・判型ごとにランダムに選び出した227冊・1,135ページの文字数を、やはりひたすら数えました。雑誌は、NDCの分類・判型ごとにランダムに選び出した53冊・265ページを実測しました。
書き言葉の実態を把握できているのか?

5年間に出版された総文字数の推計をもとに、書籍・雑誌・新聞それぞれの種類・分類の構成比を算出しました(右上の表)。しかしこの比率でサンプリングする方法では、書き言葉が生み出された実態を把握することはできても、その言葉がどれくらい流通しているかは分かりません。また書き言葉には、書籍・雑誌・新聞以外にも多くの種類があります。
そこで、書籍については、読まれているという実態を反映するよう、図書館の蔵書やベストセラーを加えました。その他のさまざまな資料も加え、性質の異なる3つのサブコーパスで構成することにしました(右図)。
原本を入手するため図書館・書店・古書店を巡る
構成が決まったら、サンプルを抽出する対象をコンピュータでランダムに選び、原本を入手します。図書館で借りたり、比較的安価なものは購入したりしました。館外への持ち出しが禁止されているものは、許可をいただいてスキャナを持ち込みスキャンしました。新聞は縮刷版を入手し、縮刷版がない場合は国会図書館のマイクロフィッシュから取得しました。
入手した原本は、出版サブコーパスと図書館サブコーパスの書籍と雑誌だけでも3万1000冊以上! 図書館の貸出申請・借り出し・返却、書店への発注・納品確認など、大がかりで複雑な作業でした。
古書店巡りの達人!?

図書館や新刊書店で入手できない資料は、古書店を次から次へと巡って探しました。*
*BCCWJの構築に携わったスタッフのコメントを紹介します。
どの部分をサンプリングする?
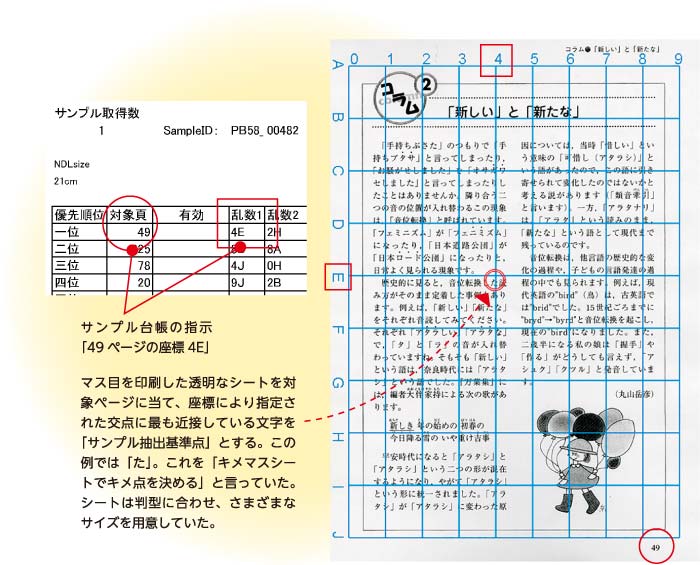
資料の原本やスキャンデータを入手できたら、サンプリングを行います。資料ごとに、何ページのどの位置からサンプリングするか、ランダムに指定します。
1つの資料から、長さの異なる2種類のサンプルを取得します。「固定長サンプル」は基準点を始点として1,000文字目までの範囲を、「可変長サンプル」は基準点を含む章や節などの言語的なまとまり(ただし上限1万字)を抽出します。
作業者泣かせの “改行なし”
可変長サンプルは、セリフ以外に改行がない文は、上限の1万字まで抽出することになっています。私が特に泣かされたのは、ロシア文学です。改行なしがずーっと続くんです。トルストイも、ドストエフスキーも。翻訳文も現代日本語として収録対象で、その翻訳文が素晴らしい文章なのですが、読みふけってしまっては文字数をカウントできません。ぐっとこらえて電卓をたたいていました。
この場合はどうする? の連続
サンプル抽出基準点はランダムに指定されるため、サンプル抽出基準点に文字がない場合もあります。その場合は、サンプル抽出基準点をサンプル台帳の乱数2、3……と変えていきます。それでも抽出できない場合は、対象ページの優先順位を下げていきます。
では、古語や外国語の文章だったら? 数式の場合は? 写真の場合は? さまざまなケースが発生します。「現代日本語で書かれた表現」が対象ですから、ひとかたまりの古語、外国語、数式や、写真、図は、原則取得対象外です。
サンプル間・作業者間で揺れが生じないように、作業規則と判断基準を細かく設定し、マニュアル化しました。そうすることで、斉一な手順で均質なサンプリングを実施しました。


真夏のコピー地獄!
暑い時期の大量コピーは、かなりの重労働でした。というのも、当時の国語研の建物の窓には、ブラインドがほとんど付いていなかったのです。しかもコピー機は窓際にありました。真夏の昼の時間帯は強い日差しが照りつけ、「そろそろ限界……」「いや、ここまで終わらせたい」という気持ちのせめぎ合いでした。今、窓という窓にブラインドが付けられているのは、この作業がきっかけでは?と勝手に考えています。





サンプル取得に使った色鉛筆。これでもほんの一部。「とても捨てられない」と記念に保管している。

著作権者から許諾をいただく

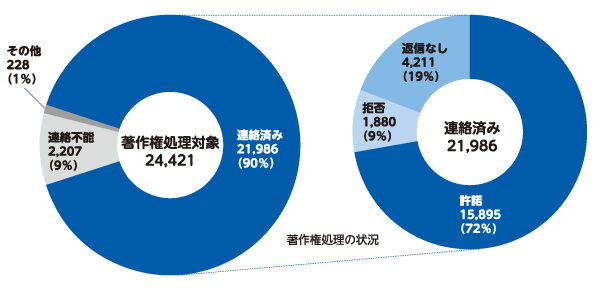
構築したコーパスを公開することは、重要な設計方針の1つでした。そのためには、収録するサンプルの著作権者に利用許諾を得る必要があります。この著作権処理に、とても苦労しました。
著作権処理が必要なサンプルは、書籍のみで2万4421件ありました。それを1件1件、地道に処理していきました。まず、サンプルの著作権者を特定します。そして連絡先を調べ、利用許諾の依頼状を送ります。連絡先が分からず、依頼状を送ることができない場合もあります。特に雑誌の場合、連絡ができない割合が書籍よりも高くなりました。
それでも根気強く連絡先を調べ、書籍については約90%に当たる2万1986サンプルの著作権者に連絡を取ることができました。
日本へのお見舞い
アメリカ在住の原著者に、最初に許諾をお願いしたときには断られてしまいました。ですが東日本大震災の後、日本へのお見舞いですと言って許諾をもらうことができました。
利用拒否になると……
とてもありがたいことに、多くのサンプルの著作権者から利用の許諾をいただけました。しかし、利用拒否の回答が来る場合もあります。
サンプリングと著作権処理は同時に並行して行っていました。利用拒否の回答が来ると、すでにサンプリングが終わっていても、そのサンプルは利用できません。対象をランダムに選んだリストから次に優先順位が高いものの原本を入手し、サンプリングをやり直さなければならず、作業計画の見直しが必要になる場合もありました。
例えば、書籍については、3つのサブコーパス合わせて1,681冊が利用不可になりました。雑誌の著作権を有する出版社に利用を拒否された例などもありました。
ようやく連絡が取れた作家さんは……
私が参加したのはプロジェクトの後期だったため、「連絡先不明」に分類された作家さんがたくさんいて、一人一人リサーチをやり直しました。そうした中、ある中国の作家さんと、幸運にも直接メールでコンタクトを取ることができました。とても丁寧なお返事と許諾もいただけて、やれやれ良かったと思っていたら……。しばらくして、ノーベル賞のニュースにその作家さんのお名前が! びっくりしました。2012年のノーベル文学賞を受賞した莫言氏です。
1億語を超える日本語書き言葉のコーパス完成!

著作権処理が済んだサンプルは、電子テキスト化します。その電子テキストを用いて形態素解析を行い、品詞など研究に必要な情報を付与します。この特集では詳細を紹介できませんが、電子化や形態論情報付与も、試行と挑戦の連続でした。そして、全てのデータをパッケージ化。
こうして2006年から5年の歳月をかけて構築を進めてきた「現代日本語書き言葉均衡コーパス(BCCWJ)」が完成し、2011年より全てのデータを収録したDVD版の頒布(有償)とオンライン公開を開始しました。現在、Web上では、オンライン検索ツール「小納言」「中納言」「NINJAL-LWP」にて利用可能です。
BCCWJを使ってみませんか
国語研では、「少納言」というオンライン検索ツールを公開しています。利用条件に同意すれば、誰でも無料でBCCWJの全文検索をすることができます。「少納言」の基本的な使い方を紹介しましょう。

① 「検索文字列」の窓に調べたい語句を入力します。例えば、「一生懸命」を検索してみます。
入力した文字列がそのまま検索されるので、その他の表記形を検索したい場合は、入力文字を変えて検索します。例えば、「一生けん命」「一生けんめい」「いっしょうけんめい」「一所懸命」「一所けんめい」「いっしょけんめい」などと入力します。
② 目的に応じて、検索対象の「メディア/ジャンル」や、刊行年代の「期間」を指定することができます。
③ 「検索」をクリックします。
前後の文脈を指定して検索したい場合は、検索ボタンの上の「こちら」をクリックして文字列を入力します。
④ 検索結果が表示されます。検索文字列の前文脈と後文脈それぞれ40字程度と、出典情報を確認することができます。検索結果のダウンロードはできません。
「一生懸命」は2,169件見つかりました。検索結果が500件以上になった場合は、その中からランダムに選んだ500件が表示されます。
検索対象の「メディア/ジャンル」や「期間」を指定することで、検索結果を絞って表示させることが可能です。「一生懸命」の場合「、メディア/ジャンル」で「雑誌」だけにすれば検索結果は76件となり、全ての用例を確認できます。
BCCWJの拡充が計画されています
BCCWJは、日本語研究をはじめ、日本語教育や国語教育、国語政策、辞書編集、自然言語処理など、さまざまな用途で使われています。BCCWJを用いた研究業績は2023年7月時点で1,784件でした。「少納言」は年60万回以上利用されています。
BCCWJの完成から10年以上たちました。BCCWJは、2011年の公開以降、更新がされていません。言葉は変化するものであり、またIT化により言葉が変化する速度は増していると言われることもあります。媒体の種類や文字数の比率も変わっていることでしょう。現代日本語の書き言葉の全体像を把握するためには、定期的なデータの追加・更新が必要です。
文化庁の施策の1つとして、令和6~10年度(2024~2028年度)にBCCWJを拡充する計画があります。2006年から2025年までの20年分の日本語書き言葉のデータを追加し、現在の1億語規模から2億語規模になる予定です。