

国語研の窓
第36号(2008年7月1日発行)
研究室から:『現代日本語書き言葉均衡コーパス』進捗報告(1)
現在,国立国語研究所研究開発部門では,『現代日本語書き言葉均衡コーパス』の構築を進めています。これは,現代日本語のさまざまな書き言葉をバランスよく集めた,1億語規模のデータベースです。2006年度から 2010年度までの 5年間に構築を進め,その後一般公開する予定です。なおこの計画の一部は,文部科学省科学研究費補助金特定領域研究「日本語コーパス」の補助により実施しています。
今回から 3回にわたって,『現代日本語書き言葉均衡コーパス』の構築について御紹介します。
書き言葉のサンプリング
コーパス構築の最初に必要となるのが,コーパスの設計,およびサンプリング作業です。コーパスの設計では,そのコーパスの中身をどのような構成にするか,どのような手続きでサンプルを収集するかを決定します。サンプリングでは,実際の書き言葉の紙面から,コーパスに格納する文章を抽出します。
コーパスの設計
『現代日本語書き言葉均衡コーパス』は,図 1に示すように,「生産実態サブコーパス」「流通実態サブコーパス」「非母集団サブコーパス」という 3つのサブコーパス(SC)から構成されます。

図1 『現代日本語書き言葉均衡コーパス』の構成
生産実態SCでは,2001年から2005年までに発行されたすべての書籍・雑誌・新聞を対象とします。流通実態SCでは,1986年から2005年までに発行された書籍のうち,都内公共図書館で広く収蔵されている書籍を対象とします。非母集団SCでは,上記二つのSCには入らないものの,現代日本語の研究にとって重要と思われる書き言葉を対象とします。
生産実態 SC・流通実態 SCでは,対象となるすべての書籍・雑誌・新聞に含まれる「文字数」を基に,統計的に厳密な方法でサンプル抽出を実施します。例えば,生産実態 SCで対象とする, 2001年から 2005年の間に発行されたすべての書籍について調査したところ,合計 317,117冊,74,911,520ページの中に, 48,539,925,351文字が含まれている,という推計結果が得られました。これを「日本十進分類法(NDC)」で分類すると,表 1のようになります。
表1 約32万冊の書籍に含まれる文字数の内訳
| N D C | 推計総文字数 | 構成比 |
|---|---|---|
| 0. 総 記 | 1,636,414,548 | 3.37% |
| 1. 哲 学 | 2,597,610,813 | 5.35% |
| 2. 歴 史 | 4,301,204,340 | 8.86% |
| 3. 社会科学 | 12,408,321,943 | 25.56% |
| 4. 自然科学 | 5,069,594,034 | 10.44% |
| 5. 技術工学 | 4,615,929,967 | 9.51% |
| 6. 産 業 | 2,196,387,437 | 4.53% |
| 7. 芸 術 | 3,258,432,447 | 6.71% |
| 8. 言 語 | 888,800,128 | 1.83% |
| 9. 文 学 | 9,341,275,486 | 19.25% |
| n. 記録なし | 2,225,954,208 | 4.59% |
| 合 計 | 48,539,925,351 | 100.00% |
この推計結果を基に,「総記」に分類される書籍からは書籍のサンプル全体の 3.37%にあたる量を,また,「文学」に分類される書籍からは全体の 19.25%にあたる量を,それぞれ無作為に抽出します。生産実態 SC全体では,書籍から 12,604サンプル,雑誌から 2,730サンプル,新聞から 1,666サンプルを取得することにより,合計約 3,500万語分のサンプルが得られると試算しています。このような方法(層別ランダムサンプリング)により,対象とする書き言葉全体の精密な縮図となるようなサンプルが得られます。
サンプリング作業
サンプリング作業では,無作為に選ばれた書籍・雑誌・新聞から,そこに書かれている文章をサンプルとして抽出します。実際の印刷紙面は,いわゆる本文だけでなく,図や表,グラフ,キャプション,脚注など,さまざまな部分から構成されています。ここから一定の基準にしたがって,コーパスに格納する文章を抽出していくことになります。
抽出するのは,印刷紙面の中からやはり無作為に選ばれた 1文字を基準として 1,000 文字を抽出する「固定長サンプル」,および文章の論理的な構造(節や章など)を単位として抽出する「可変長サンプル」という 2種類です。このためには,数万冊におよぶ書籍・雑誌・新聞を手に取ることになります。現在,国立国会図書館,東京都立図書館,立川市図書館,八王子市図書館などの諸機関から御協力を仰ぎながら,サンプリング作業を進めているところです。
(丸山 岳彦)
資料の電子化
サンプリングされた資料は,コンピュータで扱えるように電子的なテキストにします。このとき,ただ単に電子的なテキストにするだけでなく,言語研究をするときに役立つ,さまざまな情報を付加します。
『現代日本語書き言葉均衡コーパス』では, 46種類の付加情報を用意しています。付加情報には,大きく分けて,次の 3種類があります。
- 文書構造(例:章節のタイトル・範囲,段落,文)
- 文字・表記(例:誤字,ルビ)
- サンプル(例:書誌情報,著者情報)
図 2(右)は,原資料の例(警視庁:警察白書平成 14年度版 p.244,245から転載)です。図 2(左)は,この原資料を電子テキストに変換したデータです。なお,図表は前述のサンプリング作業の抽出対象外となっているため,電子テキストにはなりませんが,どのような図表があったかを示すために,キャプションを入力します。
電子テキストを見ると,原資料に明示的に書かれている本文だけでなく,いろいろな情報が付加されていることがわかると思います。例えば,図 2(右)の原資料冒頭にある,節タイトル「交通管理による環境対策」は,電子テキストでは,<titleBlock>と </titleBlock> で囲うことにより,タイトルであることが明示的に表現されています。また, titleBlock以外にも, paragraph (段落)や sentence(文)などの情報が付与されています。
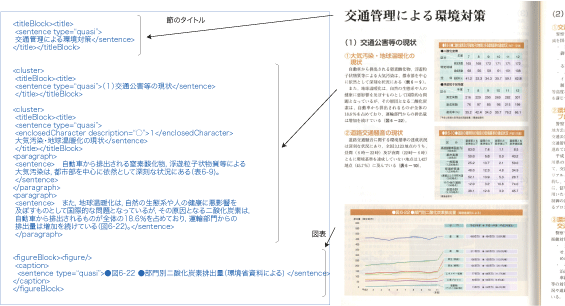
図2 原資料と電子テキストの例
このような付加情報を含め,電子テキストの形式は,「XML」と呼ばれる標準的なデータ形式で記述されます。 XML は,標準化された手続きでデータを変換したり,検索したりすることができるので,例えば,タイトルだけを抽出して調査するといったことが容易にできます。
以上のように,標準的な形式を持ち,さまざまな言語学的情報が付与されたコーパスを作成することにより,多くの人が手軽に言語研究に活用できるようになることが期待されます。
(山口 昌也)
 国立国語研究所の言語コーパス整備計画KOTONOHA:http://www.kokken.go.jp/kotonoha/
国立国語研究所の言語コーパス整備計画KOTONOHA:http://www.kokken.go.jp/kotonoha/
科学研究費特定領域研究「日本語コーパス」:http://www.tokuteicorpus.jp/
『国語研の窓』は1999年~2009年に発行された広報誌です。記事内のデータやURLは全て発行当時のものです。