

ことばの波止場
Vol. 8 (2020年9月発行)
特集 : コーパスを使って日本語の文法的な振る舞いを知る「統語コーパス」プロジェクト

言葉の規則
私たち人間が日常物事を考え、互いにコミュニケーションを行うにあたって、言葉は欠くことのできない手段です。人間は幼児期から周囲で話される言葉を自然に覚え、それがその人の母語となります。これに対して、日本人が英語、スペイン語などの外国語を習い、また外国人が日本語を学ぶときには、「文法」と呼ばれる言葉の規則を語彙とともに学習する必要があります。
言葉を母語として自然に習得し使用しているときには文法は意識されず、見えないところで働いているのですが、外国語として学ぶ際には表面に出て来ることになります。
言葉を文字で書きあらわそうとすると、文字が一直線に並ぶだけです。ところが実際には、言語は直線ではなく階層的な構造を作っているというのが言語学の常識です。たとえば、「私が読む」は文字では4文字が並んでいますが、「私」は「が」と、「読」は「む」とくっついて、「私が」と「読む」という2つのまとまりを作っています。さらにその後ろに「本」をつけて「私が読む本」とすると、「私が読む」という全体に「本」がくっついていることが分かります。このような仕組みを<統語構造>といいます。構造の理解は人間の頭の中では無意識に行われるのですが、コンピューターにそれをさせるのは至難の業です。現代ではコンピューターによる言語情報処理が実用化されようとしていますが、そのように機械に言葉を「教える」または「解析」してもらうためにも文法、つまり、文の統語構造が必要です。
文の統語構造
私たちは学校の国語や英語の時間に、主語や述語、また関係代名詞を伴った動詞文による名詞の修飾などを習いますが、これらの文法知識に共通していて、それらを支えているのが、文(センテンス)を構成している語やその集まりである句が互いに修飾したり修飾されたりする関係を持っている、という事実です。
このことは、「文は構造を持つ」と言い換えることができます。文の構造に関する規則が文法に他なりません。このように構造を持つ文を話してコミュニケーションを行うことは、質的にも量的にも限界のある脳を使って周囲のありとあらゆる事柄を表現するために人間が進化の過程で身に付けた能力です。たとえば、「子供が本を読む」という文は、おおよそ、次のように波括のまとまりごとに構造を成しています。
{ [子供] が}{ [ [本] を] 読む}
このうち、一番外側の波括弧で示した部分、「子供が」と「本を読む」は、それぞれ主語(名詞句)と述語(動詞句)に相当します。このような構造についての情報が注釈付けされた言語データを集積することで、実際に使われている語や文をデータとして利用して言葉の文法を研究することが可能となります。また、そのような規則をコンピューターに与えて、人間の言語を解析することもできるようになります。
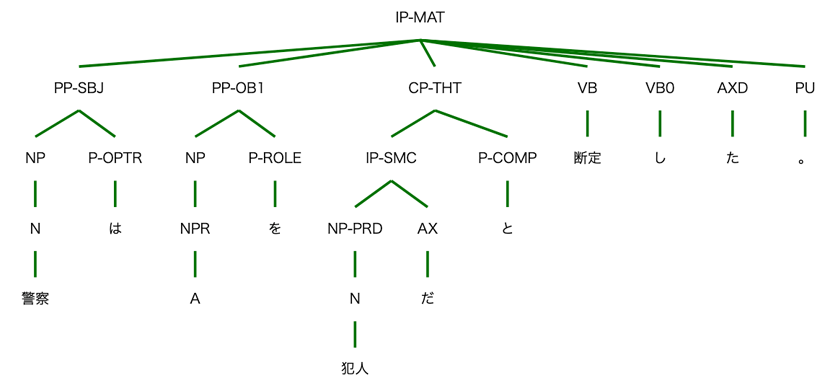
元々、人工知能の研究によって生まれた概念に上述の「名詞句」(図1 ではNP)、「後置詞句」(図1 ではPP)のような「句構造」というものがあり、近年になってからは、これを文(図1 ではIP-MAT)の構造の表示に利用して様々な研究が行われています。句構造を使えば文の意味が正しく扱われることが知られています。
「統語コーパス」プロジェクト
「統語コーパス」プロジェクトが取り組んでいるのは、上で示したような、句構造、述語に対する主語・目的語・付加詞といった関係、さらには、名詞修飾構造(「友達から聞いた噂」「大統領が辞任した噂」)、受動文(「私は殴られた」「私は雨に降られた」)、使役文(「子どもに本を読ませた」)、条件節(「安ければ、買おう」)、引用節(「彼は来ると言った」)などの、文の統語・意味構造に関する様々な情報の注釈を備え、それを使って用例を検索することのできる現代日本語コーパスの開発と公開です。
これまで、日本国内では様々なコーパスが作られてきましたが、その多くは上に挙げたような情報を持っていません。統語情報を注釈付けしたコーパスはツリーバンク(treebank)と呼ばれます。海外では1960年代からすでにツリーバンクの構築が進められ、言語研究に利用されていますが、日本語についてはそのようなコーパスは存在しませんでした。したがって、「統語コーパス」プロジェクトは国内初の本格的なツリーバンク構築の試みと言うことができます。我々は、日本語ツリーバンクは、日本語研究への利用だけでなく、学校における日本語(国語)の学習や、外国語としての日本語の学習にも役に立てることができるはずであり、さらに将来的には、自動翻訳や人工知能の開発にも貢献できるであろうと考えています。
NPCMJコーパスと検索ツール
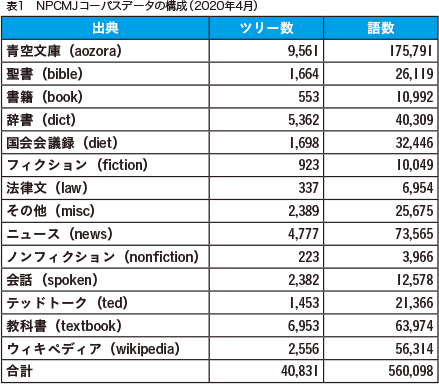
「統語コーパス」プロジェクトにおけるコーパス構築の成果は、「統語・意味解析情報付き現代日本語コーパス」(NINJAL Parsed Corpus of ModernJapanese、以下、NPCMJ)として順次、一般公開しています。表1はNPCMJ のデータを出典ごとに分類したものです。この表から分かるように、NPCMJ には2020年4月現在、約4万文(ツリー)、語数にして約56万語のデータが収録されています。データはすべて、漢字仮名混じりとローマ字の両方で表記されており、全データ、あるいは次ページで紹介する検索ツールを使った検索結果を自分のコンピューターにダウンロードすることができます。
コーパスを利用するには検索ツールが必要です。「統語コーパス」プロジェクトでは、NPCMJのための専用の検索ツールの開発も行っています。ひとつは、初中級者向けのNPCMJ Explorer、もうひとつは、中上級者向けのNPCMJ Searchです。NPCMJ Explorerは、単純な文字列検索と、特定の文法項目に関する用例の検索という2種類の検索手段を備えたツールです。文法項目として、益岡隆志・田窪行則(1992)『基礎日本語文法』(くろしお出版)で解説されている136の項目から73項目を取り上げ、各項目のラベルをクリックするだけで、利用者が複雑な検索式を作成しなくても、用例が表示される仕組みになっています。ジャンル(表1 における「出典」)ごとの頻度を調べるためのジャンル指定機能もあります。NPCMJ Search では、品詞や句・節に与えられたラベルや、ラベルとラベルの関係を検索式によって指定しながら用例の検索を行います。どちらのツールでも、検索結果を一覧表示させたり、木構造で表示させたりすることができます。
以上で紹介したNPCMJのデータおよび検索ツールは、「統語コーパス」プロジェクトのウェブサイト(http://npcmj.ninjal.ac.jp/)からアクセスすることができますので、ぜひお試しください。
NPCMJを使って日本語の文法的な振る舞いを知る
先に述べたとおり、NPCMJは文の統語・意味構造に関する様々な情報を持っています。そのため、特定の構文を検索し、それが実際にどのように使われているかを観察することが比較的簡単にできます。ここでは、その例として受動文、および文中の主語と目的語の語順をとりあげ、その使用実態を頻度という観点から見てみましょう。
受動文
日本語の受動文は直接受動と間接受動(「迷惑の受け身」「被害の受け身」とも)の2つに大別されます。以下の2つの例は、どちらも述語に助動詞の「れ(る)・られ(る)」が含まれますが、1つ目が直接受動の、2つ目が間接受動の例です。
私はさんざんに殴られた。
太郎は雨に降られた。
直接受動文の主語は、対応する能動文「〇〇が私を殴った」の目的語であり、能動文の主語を受動文の中に表現する場合は、「に」や「によって」などの助詞をつけて表します。直接受動文は世界の多くの言語に見られるものです。一方、間接受動文には対応する能動文がありません。「太郎は雨に降られた」の「太郎」は「雨が降った」という文の中に表現することのできない要素です。このような間接受動を持つ言語は世界にはそれほど多くないと言われています。また、日本語には「太郎は先生に作文をほめられた」のように、能動文「先生は太郎の作文をほめた」の目的語の中の修飾語(=所有者)が、受動文の主語になるというものもあります。これは所有者受動と呼ばれ、直接受動と間接受動の中間的なものとする立場と、間接受動の一種と見なす立場がありますが、NPCMJ では後者の立場をとっています。
以上のように文法的な観点から直接受動と間接受動は異なったものだと考えられるのですが、では、実際の言語使用の中で、これら2つはどのように異なっているのでしょうか。このような違いは、もちろん、私たちが直感的に説明できるようなものではありません。しかし、コーパスを利用し、頻度を比べることによってその違いに迫ることが可能です。
NPCMJ では、直接受動を表す助動詞には PASS というラベルが、間接受動を表す助動詞には PASS2 というラベルが与えられていますので、このラベルを手がかりに両者を別々に検索することが可能です(図2 を参照)。このようにして約4万文のデータを検索すると、直接受動文は3448例、間接受動文は170例という結果が得られます。実際に書かれたり話されたりした言葉の中では、両者の使われる頻度が全く違っている、言い換えると、頻度の点で非対称性があるということになります。

このような使用実態に関する情報は、外国人のための日本語教育に役立てることもできます。例えば、より頻繁に使われる直接受動を先に教え、その後、あまり使われない(しかし、日本語の表現としては重要な)間接受動を教えるという風に、文法項目の導入順を使用頻度という客観的な指標に基づいて決めることができるようになるからです。また、コーパスで得られた用例は、教科書の例文とは異なり、生きた言葉を反映したものですから、学習者は当該の文法項目をより自然な用例とともに覚えることができます。
主語と目的語の語順
日本語は語順の比較的自由な言語です。例えば、
太郎が花子をほめた。
花子を太郎がほめた。
のように、名詞句が「〜が~を」の順番に並んでも、「〜を〜が」の順番に並んでも日本語の文として成立します。ただし、母語話者は直感的に「〜が〜を」の方が普通で、「〜を〜が」の方が特別な順番だと考えます。NPCMJ で2つの語順の割合を調べると、「〜が〜を」は98%、「〜を〜が」は2%という割合で、しかも「〜を〜が」の方は「を」の前の名詞句に修飾語があるなど、「が」の前の名詞句よりも長いときに使われる傾向が見られると報告されています(Kishimoto and Pardeshi 2019)。つまり、こちらが普通で、こちらが特別という直感は、実際の言語使用における頻度の高低と結びついていると考えられます。
では、
太郎が花子にプレゼントを送った。
太郎がプレゼントを花子に送った。
のような「〜が〜に〜を」の順番と「〜が〜を〜に」の順番はどうでしょうか?この2つの順番についてどちらが普通でどちらが特別ということを直感的に判断するのは難しいような気がします。NPCMJで割合を調べると、「〜が〜に〜を」が62%で、「〜が〜を〜に」が38% と先に見たほどの大きな差は見られないものの、「〜が〜に〜を」の方が使用頻度が高く、また、「〜が〜を〜に」の方には、「を」の前の名詞句が旧情報という傾向があると報告されています(Kishimoto and Pardeshi 2019)。
今後の展望
現在、「統語コーパス」プロジェクトでは、NPCMJのデータ量を6万文(ツリー)に増やすことを目指して活動しています。また、NPCMJを使ったオンラインの練習問題を解きながら統語論を学ぶという、言語学を専門とする学生向けの教材が完成間近です。
それに加えて、大人による標準語のデータとは異なる日本語のバリエーション、具体的には、6歳までの子供の言葉と津軽方言についてもツリーバンクの構築を進めています。どちらも世界的に類例のほとんどない試みですが、子供の言葉のツリーバンクからは、子供がどのような順番で様々な表現・構文を習得していくのか、その過程(言語習得過程)が鮮明に見えてくるはずです。また、方言のツリーバンクは、方言における文法体系をよりきめ細かく記述するための基盤となることが期待されます。
【引用文献】
Hideki Kishimoto, Prashant Pardeshi (2019) “ Parsed Corpus as a Source for Testing Generalizations in Japanese Syntax.” In Prashant Pardeshi, Alastair Butler, Stephen Horn, Kei Yoshimoto, Iku Nagasaki(eds). Exploiting Parsed Corpora: Applications in Research, Pedagogy, and Processing. LiLT (Linguistic Issues in Language Technology), Vol. 18, Issue 2, pp.1–24(special issue published online).
(国立国語研究所・教授/プラシャント・パルデシ
名古屋大学・特任講師/長崎郁)